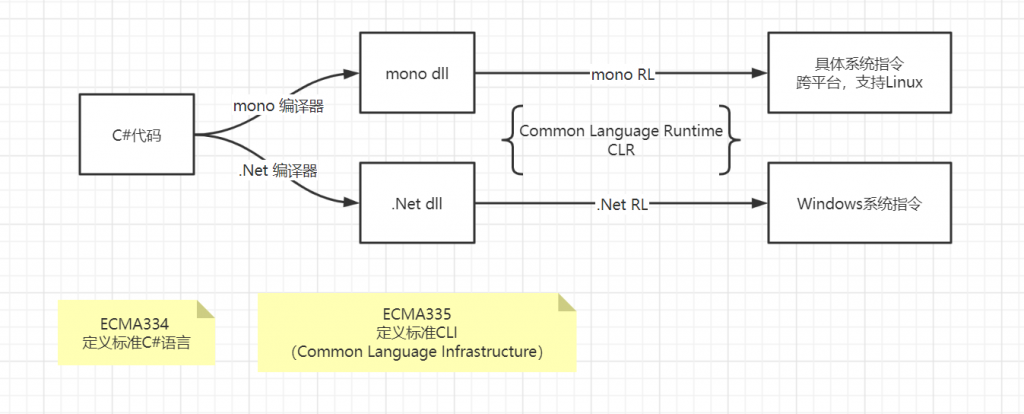
时隔3年终于又有线下的技术分享大会了,这几年UE的技术发展确实很快, 这次有机会来参加UE的技术分享还是挺开心的。
第一天前两场都是老外的开场,介绍UE5的新功能,这些官网都有详细介绍,其中比较有意思的是UEFN平台,是堡垒之夜Mod编辑器加分享平台,可以利用堡垒之夜的资源制作自己的玩法、关卡提供给其他玩家玩。平台也提供推广、付费分成这些。UGC确实是一个风口,Epic在这方面也是通过UEFN平台在发力。
《 基于虚幻引擎的数字孪生开发平台客户端搭建 》
因为A区索尼在卖广告,就跑来B区听了,意外发现很有意思。现在制造业里面不仅会使用UE来做一些产品展示,还会通过图像识别或者在生产线中加装传感器来收集各种数据,然后在UE里面还原一个生产(监控)现场,再利用游戏引擎自带的碰撞体或者其他Trigger机制来触发他们关心的各种事件,配合蓝图来做后续各种控制。这就好比现实工厂是服务端,产生逻辑数据(或操作),UE作为客户端同步构建现场,再触发各种事件以后通知回服务器(工厂)。分享里还举一个状态同步及一个帧同步的例子。状态同步就是通过图像识别获取汽车信息及位置,在UE里还原汽车的速度,行驶轨迹,检测是否越线超速这些。帧同步的例子就是生产流水线上有传送带和升降机等各种机械信号,这些信号就是针对流水线上物品的操作,通过帧同步的方式下发操作,在UE内(客户端)还原出实际的物品状态,再通过各种Trigger监听是否有意外情况的发生。而他们使用的蓝图节点也是定制的,通过反射自定义数据自动生成他们需要的蓝图节点。网络同步、自定义的图像化编程,这些都是最近这几年有在做的东西,想不到这些技术游戏技术与制造业已经能如此结合,真是大开眼界。
Continue reading